
Notes: Walking through all inputs, one at a time, weights are adjusted to make correct prediction.If the classification is linearly separable, we can have any number of classes with a perceptron. Note that there is one weight vector for each class. Images from clker
Data has to be ideally normalized so that larger values donot influence the classifier. In this case we used tanh(x) function. The restricted range could have been the range [0,1] if sigmoid function was used.
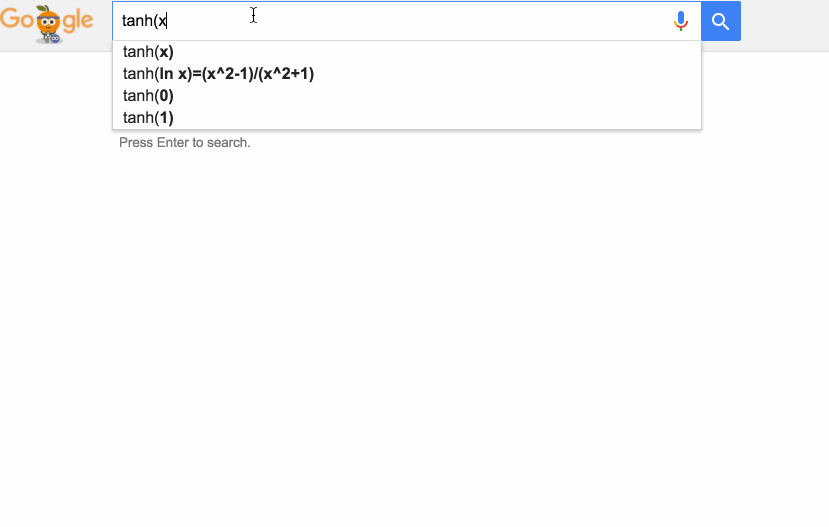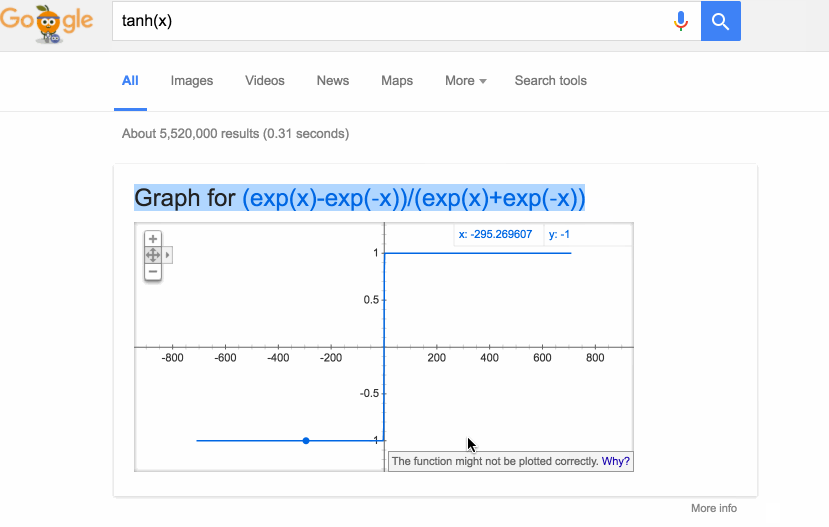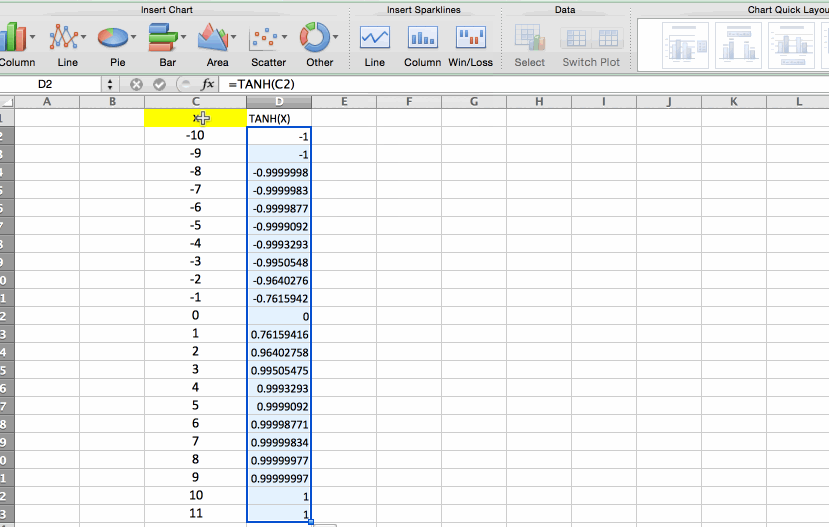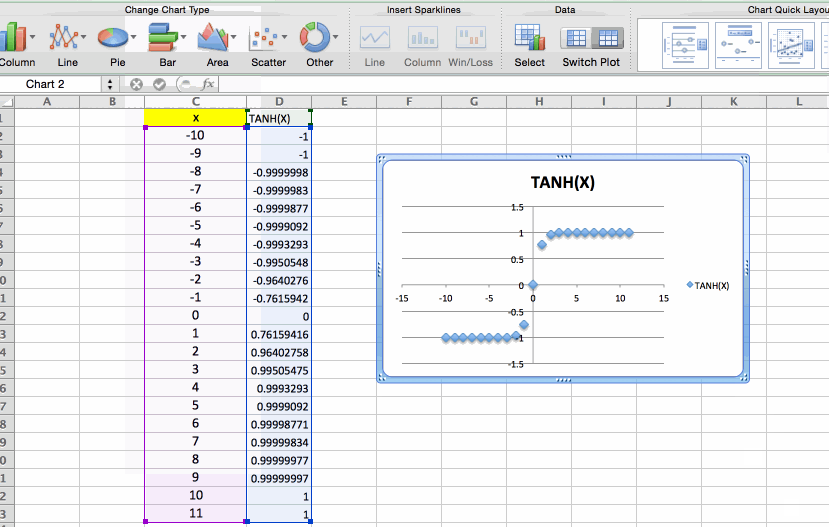
Fig: Demonstrating how tanh(x) function squeezes large values to a range [-1,1]
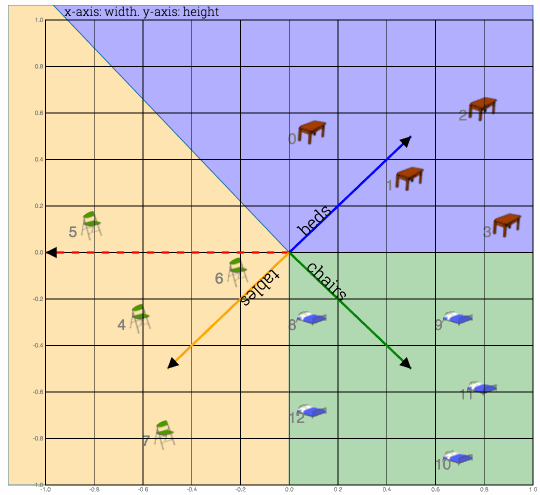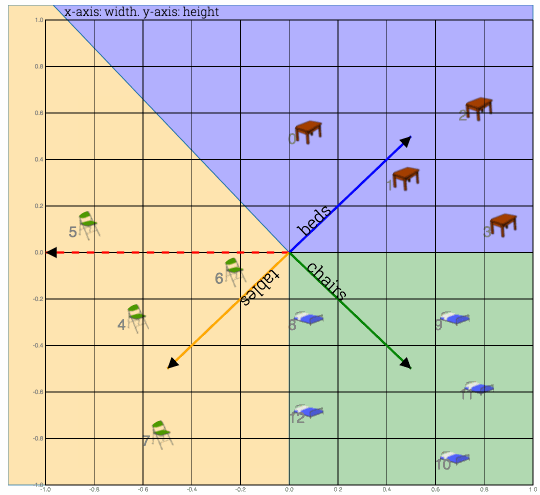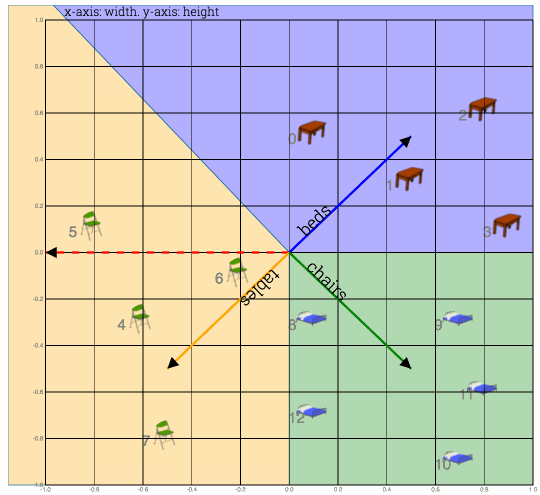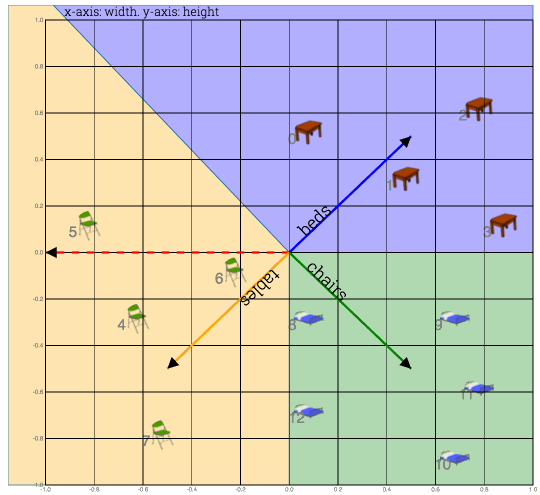
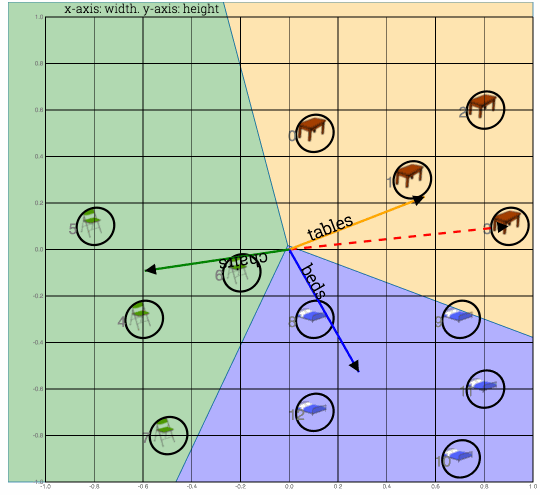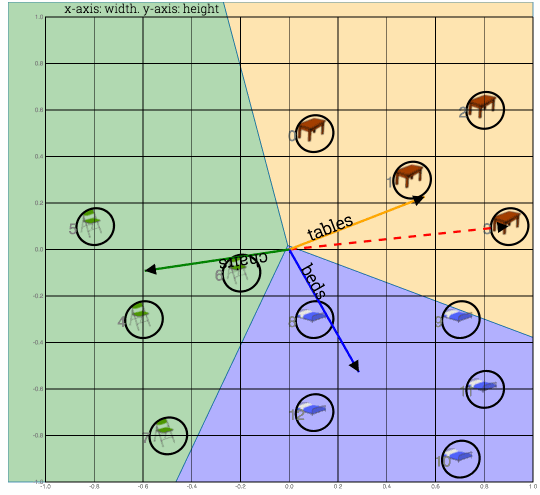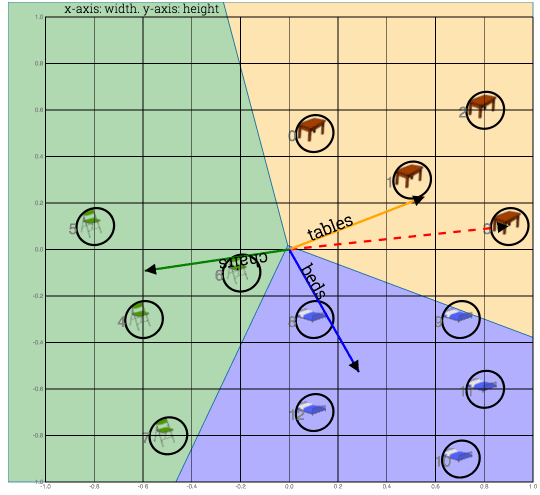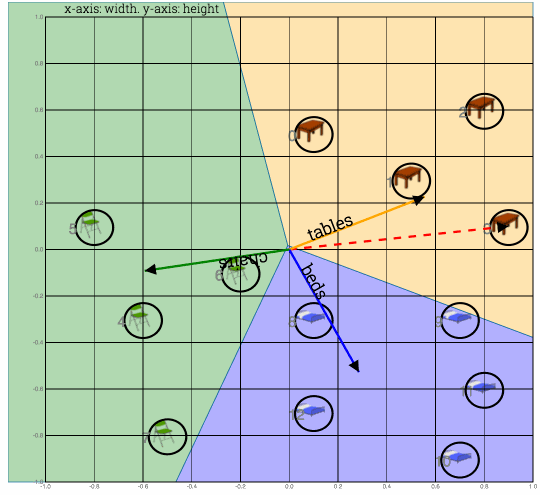
Weight vectors for each class of furtniture are initialized with random weights. Weights, also called parameters or coefficients are adjusted change to fit model to data. Which simple means that weights are changed to capture most meaning in data
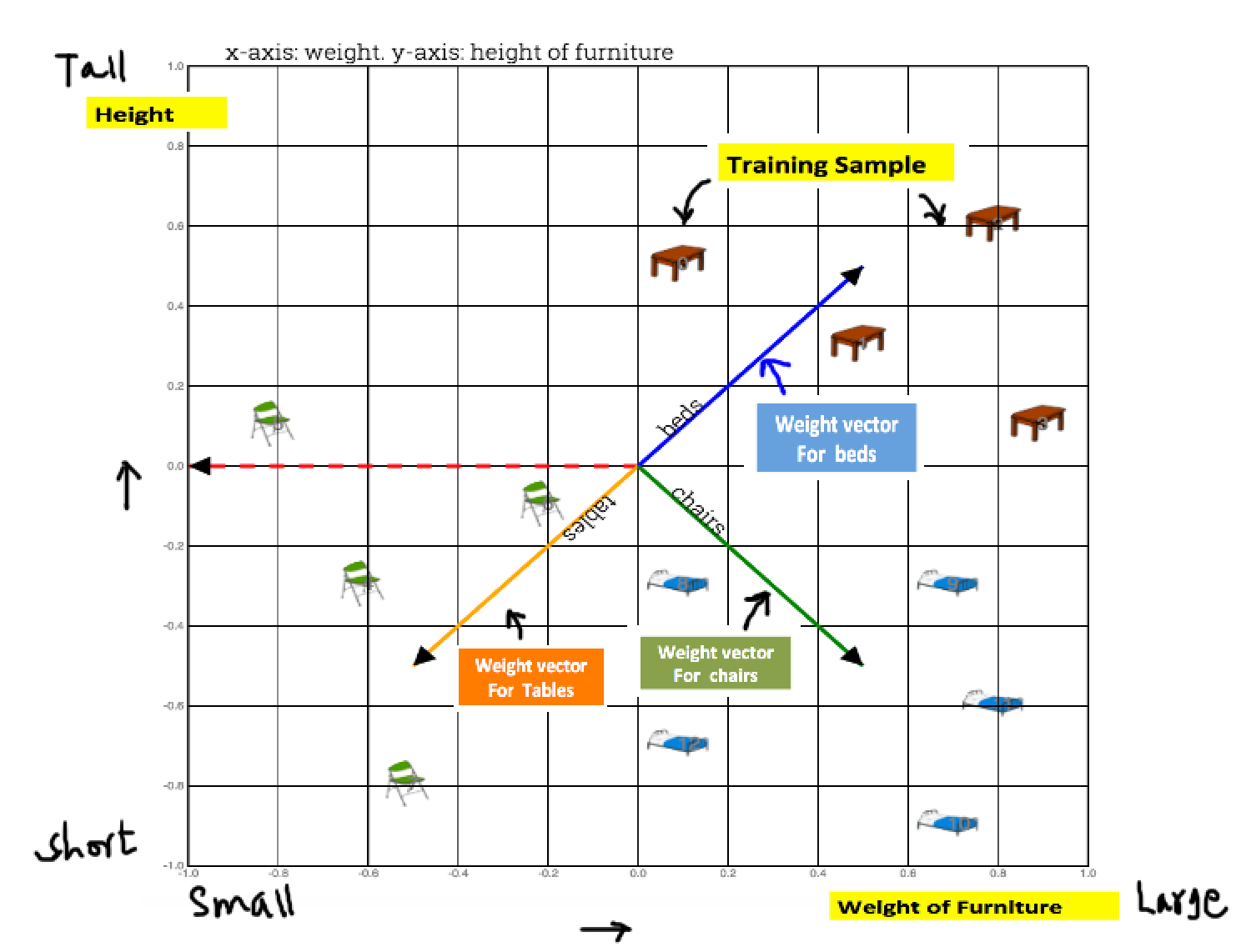
Fig1: Training samples. Height vs weight. To plot multidimensional data in 2-d refer to TSNE
Walk through all training examples one at time.
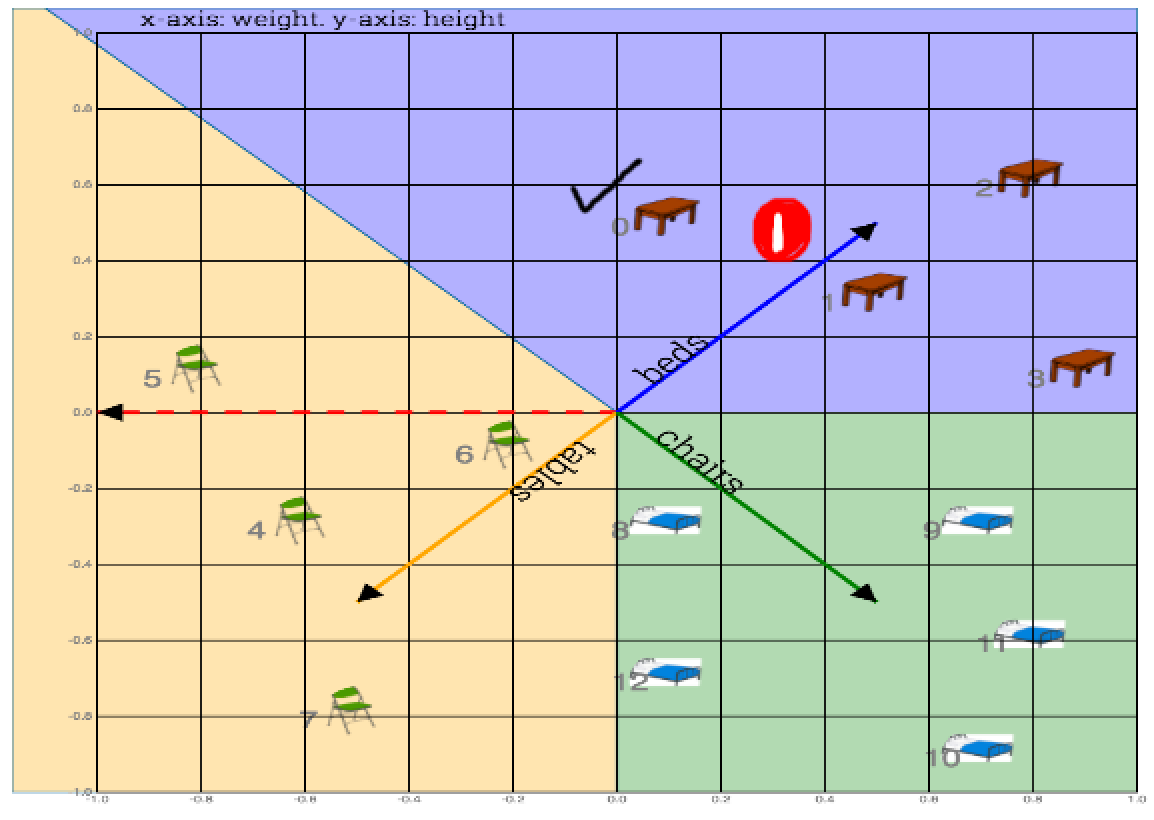
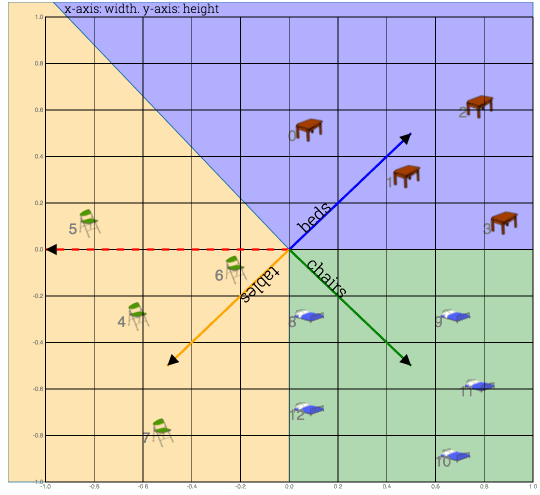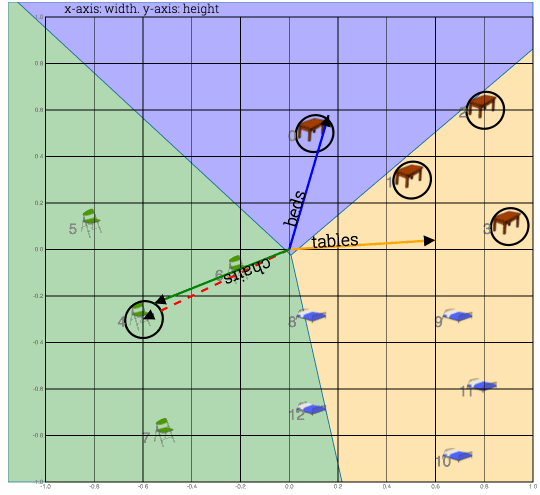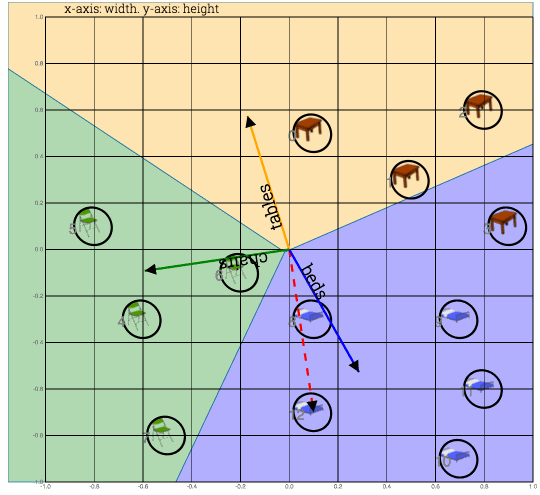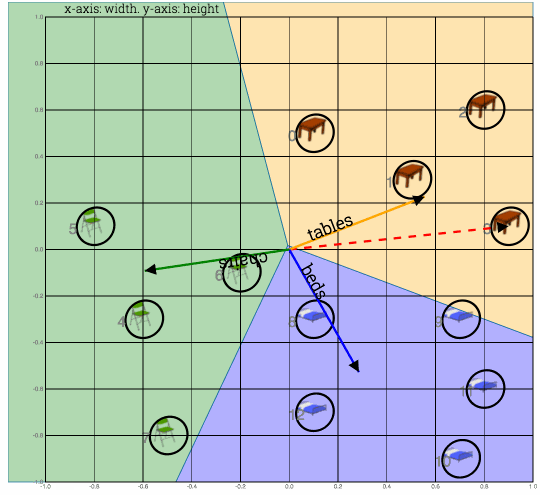
Fig: Weight vectors (one each for table, chair and beds) are randomly initialized. Goal is to align them towards correct cluster
1) Take dot product of table#0 with all weight vectors
2) Which ever weight vector has highest dot product wins. Label on that vector is your prediction
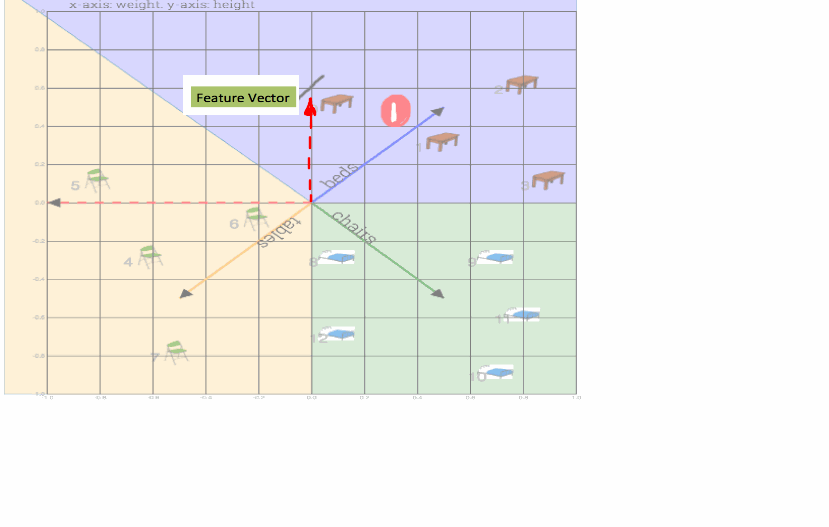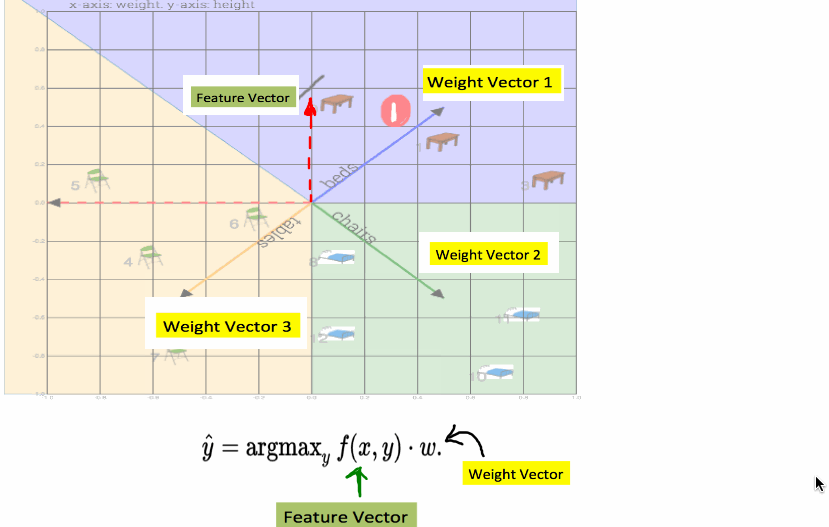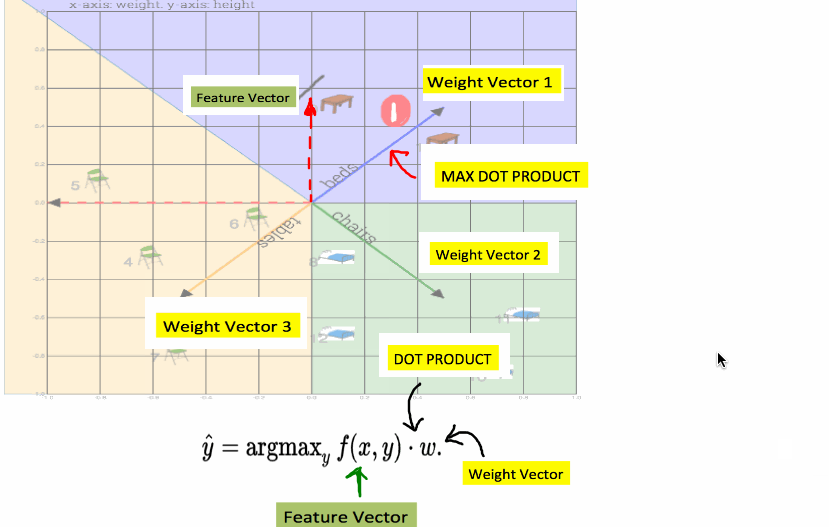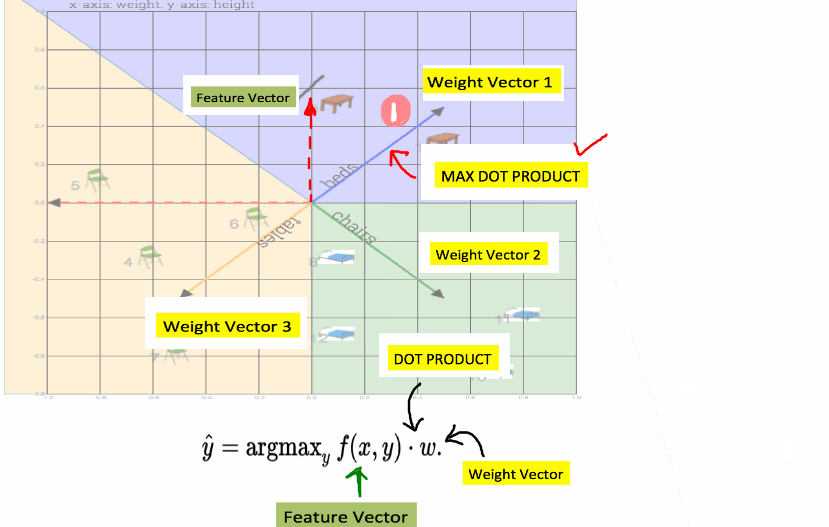
Fig: Shows calculation of dot product to compute a class (table or bed or chair). In this case closest weight vector was beds vector, while feature vector was a table vector. So prediction was wrong
Move the weight vector, with max dot product, away from feature vector by subracting it from the curent training input.Bring the expected vector close by adding the expected vector to the current feature vector. This procedure is called delta rule.
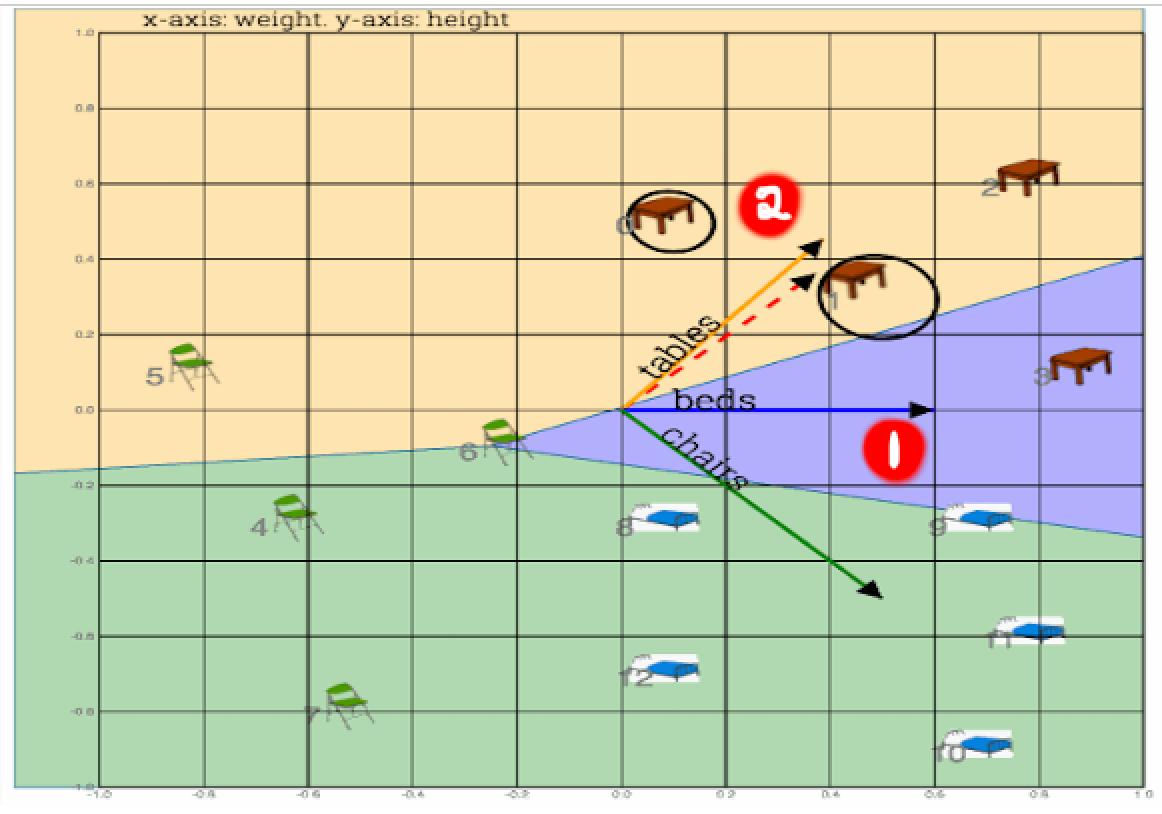
Fig: Here 1) Bed vector is moved away from table#0 and 2) Table vector is borught close to table#0
Move the weight vector close to data point. Choose a lower learning rate to ensure that there are no huge jumps. Which could break convergence.
Learning rate matters. If learning rate is large, convergence takes longer
Weight vectors have to be normalized. That is their size has to be clipped to standard size
Conditions have to be set to stop learning after weights have converged.
Example perceptron
Perceptron Fails to converge with when data is not seperable. Weights might trash allover even when network seemed to have converged
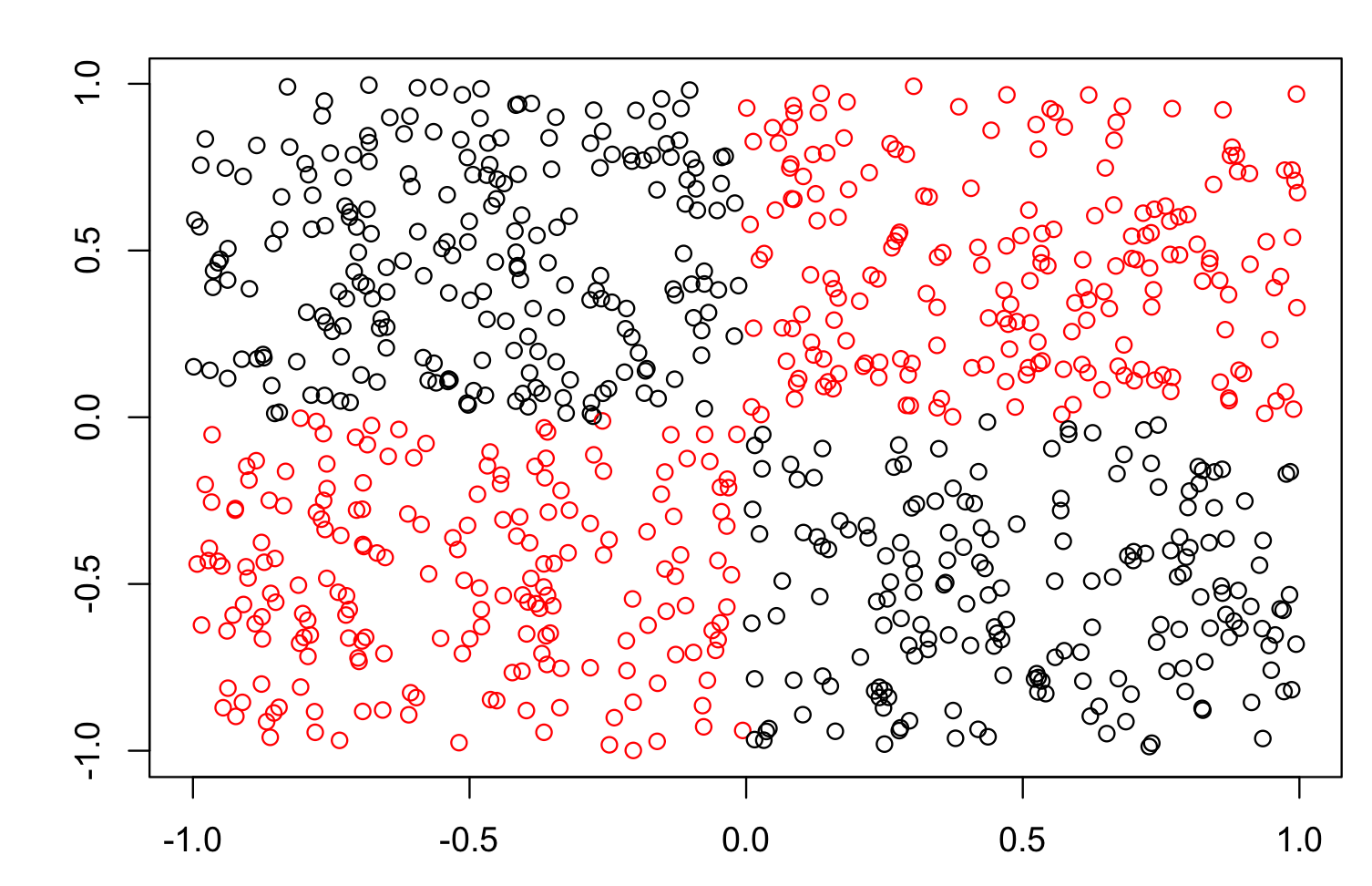
Fig: XOR data plot. Perceptrons donot converge with such feature vector pattern. Graph data is taken from mlbench package in R. Perceptrons work only with linearly seperable data.
Perceptron doesn’t check to see is the chosen weight is most optimal.
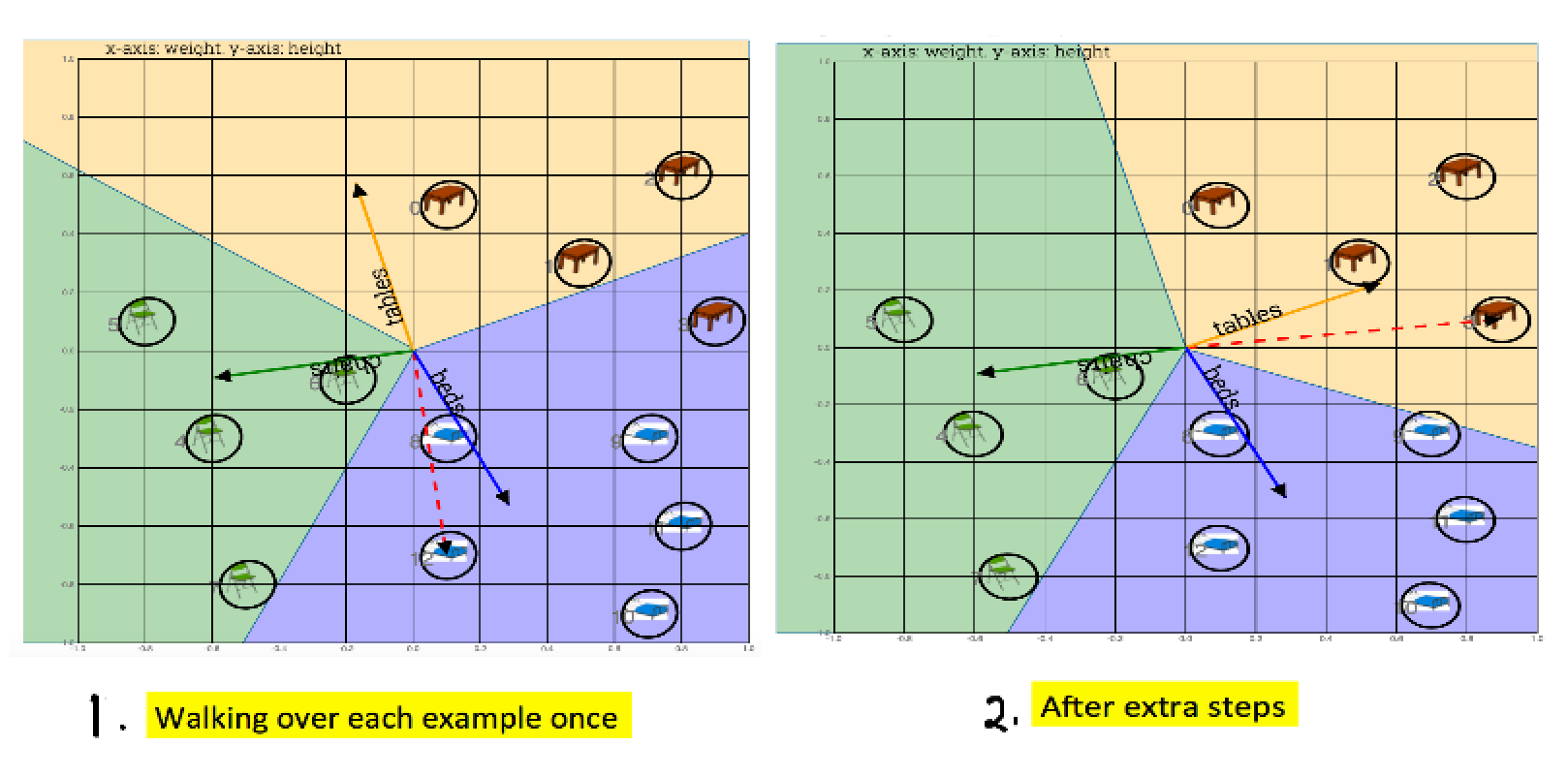
Fig: In this case, chosing additional walks through input training set improves the weights, but it doesn’t check if this would be most optimal.
With large training set, error rate is low, but with new test it doesn’t generalize, it just memorizes
Use hidden layers with Multi layer perceptrons to include interaction operator across variables
Implement a cost function to final optimal iteration to stop at reasonable convergence
Delta rule with backpropogation to adjust weights based on error feedback
Pocket Algorithm, Adatron optimization and Support vector machines Reference
Combine several of them together as is done in multi-layer networks
Weight vectors could explode or diminish quickly. That is, weight vector could get too long after subsequent additions, or could beccome too small. To overcome that problelm, I normalized the weight vectors to a restricted length.
It is hard to figure out when to stop training. For this tutorial purposes, I hardcoded, number of iterations. It is highly probable that you might lose a converged state with small weight updates. Use a cost function to monitor accurate and inaccurate clasificatons to avoid over training.
In #MachineLearning, Cross Entropy is used to compare approximate models. Tutorial: https://t.co/cScdGGutXD #DataScience by @pavanmirla pic.twitter.com/mYuh2m6ov5
— Kirk Borne (@KirkDBorne) October 11, 2016
Build a Neural Net to solve the Exclusive-OR (XOR) problem: https://t.co/QmH0wzwOdA by @pavanmirla #DataScience #MachineLearning
— Kirk Borne (@KirkDBorne) September 16, 2016
Intuition behind concept of gradient vector: https://t.co/vejnoSADmr #DataScience #MachineLearning by @pavanmirla pic.twitter.com/DKcX1p9X4m
— Kirk Borne (@KirkDBorne) July 17, 2016
Maximum Likelihood Estimate (MLE) and Logistic Regression simplified: https://t.co/CUdOhpP4ko #DataScience #MachineLearning by @pavanmirla
— Kirk Borne (@KirkDBorne) July 25, 2016
Reference Interaction term