- Learn what is benefit of using embeddings to represent categorical data
- Learn how to create embeddings from Categorical columns using Tensorflow
- Learn how to host your build model using Tensorflow for inference
Author: Pavanmirla@perceptron.solutions
Embedding is just a numeric representation of an entity. Entity could be level in a categorical column, or word in a sentence. Vector [ numeric array representation] of an object/entity is called Embedding
Applications
Model Features
Feature compression
Nearest Neighbor search
Transfer Learning
Step1- Install virtualenv package to isolate your python project
pip install virtualenvStep2 - Create an environment - say my_python3_environment. Install Python3 in this environment
virtualenv --system-site-packages -p python3 ./my_python3_environmentStep3- Activate this environment to install additional packages
source ./my_python3_environment/bin/activateStep4- Now you will be in a virtual environment. Now install tensorflow
pip install tensorflow
Create a python file to source your csv data
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import feature_column
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
#check if eager mode is enabled
tf.executing_eagerly()
URL = 'https://storage.googleapis.com/applied-dl/heart.csv'
dataframe = pd.read_csv(URL)
dataframe.head()
train,test = train_test_split(dataframe,test_size=0.2)
train,val = train_test_split(train,test_size=0.2)
print(len(train))
print(len(val))
print(len(test))def df_to_dataset(dataframe, shuffle=True, batch_size=32):
dataframe= dataframe.copy()
labels = dataframe.pop('target')
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size= len(dataframe))
ds= ds.batch(batch_size)
return ds
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
for feature_batch, label_batch in train_ds.take(1):
print('Every feature:', list(feature_batch.keys()))
print('A batch of ages:', feature_batch['age'])
print('A batch of targets:', label_batch )
feature_columns_all = []
#numeric_cols
for header in ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca']:
feature_columns_all.append(feature_column.numeric_column(header))#bucket columns
age = feature_column.numeric_column("age")
age_buckets = feature_column.bucketized_column(age, boundaries = [18,25,30,35, 40,45,50,55,60, 65])
feature_columns_all.append(age_buckets)
)vocab_thal = dataframe.loc[:,'thal'].unique().tolist()
thal_fc_cat = feature_column.categorical_column_with_vocabulary_list('thal',vocab_thal)
thal_one_hot = feature_column.indicator_column(thal_fc_cat)
feature_columns_all.append(thal_one_hot)
thal_fc_embedding = feature_column.embedding_column(thal_fc_cat, dimension=8)
feature_columns_all.append(thal_fc_embedding)
crossed_fc= feature_column.crossed_column([age_buckets, thal_fc_cat],hash_bucket_size=10)
crossed_fc_ind = feature_column.indicator_column(crossed_fc)
feature_columns_all.append(crossed_fc_ind)
feature_layer = tf.keras.layers.DenseFeatures(feature_columns_all)
batch_size = 32
train_ds = df_to_dataset(train, batch_size = batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size= batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
import datetime
log_dir="logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
checkpoint_path="logs/checkpoint/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, save_weights_only= True, verbose=1)
model.fit(train_ds, validation_data=val_ds,callbacks=[tensorboard_callback,checkpoint_callback ], epochs=5)
tensorboard --logdir logs/fit
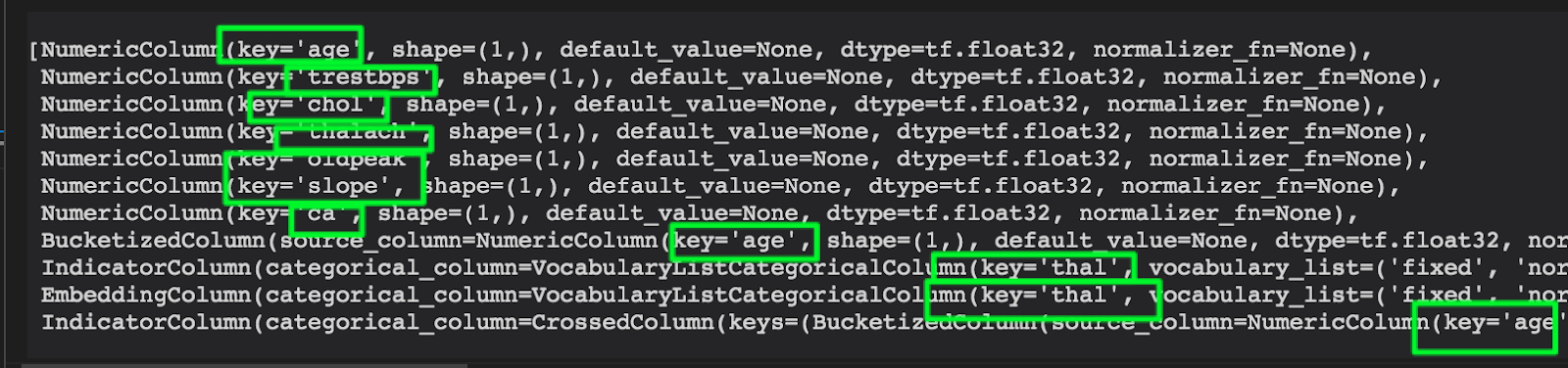
feature_layer.get_config()['feature_columns'].keys()
[{'class_name': 'NumericColumn',
'config': {'key': 'age',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'BucketizedColumn',
'config': {'source_column': {'class_name': 'NumericColumn',
'config': {'key': 'age',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
'boundaries': (18, 25, 30, 35, 40, 45, 50, 55, 60, 65)}},
{'class_name': 'IndicatorColumn',
'config': {'categorical_column': {'class_name': 'CrossedColumn',
'config': {'keys': ({'class_name': 'BucketizedColumn',
'config': {'source_column': {'class_name': 'NumericColumn',
'config': {'key': 'age',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
'boundaries': (18, 25, 30, 35, 40, 45, 50, 55, 60, 65)}},
{'class_name': 'VocabularyListCategoricalColumn',
'config': {'key': 'thal',
'vocabulary_list': ('fixed', 'normal', 'reversible', '1', '2'),
'dtype': 'string',
'default_value': -1,
'num_oov_buckets': 0}}),
'hash_bucket_size': 10,
'hash_key': None}}}},
{'class_name': 'NumericColumn',
'config': {'key': 'ca',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'NumericColumn',
'config': {'key': 'chol',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'NumericColumn',
'config': {'key': 'oldpeak',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'NumericColumn',
'config': {'key': 'slope',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'EmbeddingColumn',
'config': {'categorical_column': {'class_name': 'VocabularyListCategoricalColumn',
'config': {'key': 'thal',
'vocabulary_list': ('fixed', 'normal', 'reversible', '1', '2'),
'dtype': 'string',
'default_value': -1,
'num_oov_buckets': 0}},
'dimension': 8,
'combiner': 'mean',
'initializer': {'class_name': 'TruncatedNormal',
'config': {'mean': 0.0,
'stddev': 0.35355339059327373,
'seed': None,
'dtype': 'float32'}},
'ckpt_to_load_from': None,
'tensor_name_in_ckpt': None,
'max_norm': None,
'trainable': True}},
{'class_name': 'IndicatorColumn',
'config': {'categorical_column': {'class_name': 'VocabularyListCategoricalColumn',
'config': {'key': 'thal',
'vocabulary_list': ('fixed', 'normal', 'reversible', '1', '2'),
'dtype': 'string',
'default_value': -1,
'num_oov_buckets': 0}}}},
{'class_name': 'NumericColumn',
'config': {'key': 'thalach',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}},
{'class_name': 'NumericColumn',
'config': {'key': 'trestbps',
'shape': (1,),
'default_value': None,
'dtype': 'float32',
'normalizer_fn': None}}]w =feature_layer.get_weights()[0]
thal_fc_embedding = feature_column.embedding_column(thal_fc_cat, dimension=8)
feature_columns_all.append(thal_fc_embedding)example_batch = next(iter(train_ds))[0]
all_w = feature_layer(example_batch).numpy()
tf.keras.models.save_model(model, "model_saved_gfce") # without extension .h5, only string of your model
new_model = tf.keras.models.load_model("model_saved_gfce") # as you have saved for the first time, without extension again.
loss, accuracy = new_model.evaluate(test_ds)
print("Accuracy", accuracy)
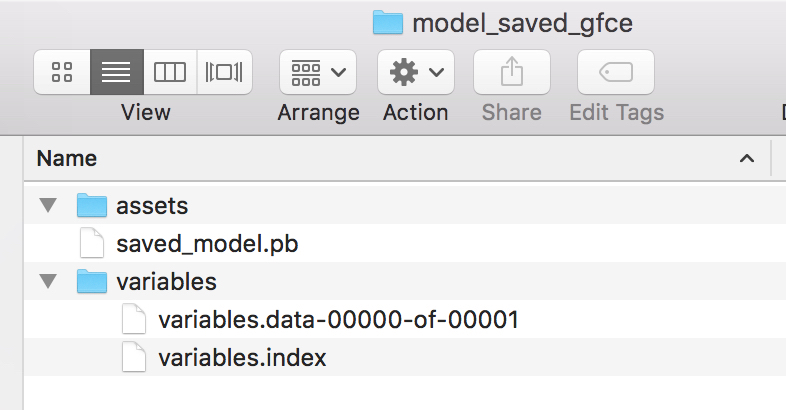
There is another way to save . Refer to documentation always. Bookmark these pages and get familiar with the structure to navigate. Use the extension model_saved_gfce/00000002 when you save model using tf.keras.models.save_model function call
tf.keras.models.save_model(model, "model_saved_gfce/00000002") # without extension .h5, only string of your model
(base) Pavans-MBP:google_tf_functions_examples pavanmirla$ ls -l model_saved_gfce
total 0
drwxr-xr-x 00000001
drwxr-xr-x 00000002batch_size_all = len(train)
dataframe_ds = df_to_dataset(train, batch_size= batch_size_all)
example_batch = next(iter(dataframe_ds))[0]
all_w = feature_layer(example_batch).numpy()
all_w_df= pd.DataFrame(all_w)
all_w_df.to_csv("months_embedding_space.csv",sep="\t", index=False, header=False)This book on reinforcement learning suggested TensorBoardX.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=10, random_state=0).fit(all_w_df)
groups = kmeans.predict(all_w_df)
groups_df = pd.DataFrame(groups, columns= ['cluster_group'])
groups_df.to_csv("meta_data_embeddings.tsv", sep='\t',index= False, header = False)
Git clone this standalone tensorflow projector
tf.keras.utils.plot_model(model, 'image_output_model.png', show_shapes=True)
Where to find Keras related documentation?
docker run -p 8500:8500 \
--mount type=bind,source=/Users/pavanmirla/projects/<your_folder>/google_tf_functions_examples/model_saved_gfce,target=/models/model_saved_gfce \
-e MODEL_NAME=model_saved_gfce -t tensorflow/serving &This format seems to be required for Whatif Tool.Link for the helper functions.

But, how to write it back to a tfrecord file? This code below does not work. Here is t
Example for scenario analysis. Variable values are replaced with average values. Shown below
request_data = { 'instances':
[
{
'dep_delay': dep_delay,
'taxiout': taxiout,
'distance': 160.0,
'avg_arr_delay': avg_arr_delay,
'dest': 'CDV'
}
for dep_delay, taxiout,avg_arr_delay in
[ [ 16.0, 13.0, 67.0],
[ 13.3, 13.0, 67.0],
[ 16.0, 16.0, 67.0],
[ 16.0, 13.0, 4.0]
]
]
}
#output
request_data
{'instances': [{'dep_delay': 16.0,
'taxiout': 13.0,
'distance': 160.0,
'avg_arr_delay': 67.0,
'dest': 'CDV'},
{'dep_delay': 13.3,
'taxiout': 13.0,
'distance': 160.0,
'avg_arr_delay': 67.0,
'dest': 'CDV'},
{'dep_delay': 16.0,
'taxiout': 16.0,
'distance': 160.0,
'avg_arr_delay': 67.0,
'dest': 'CDV'},
{'dep_delay': 16.0,
'taxiout': 13.0,
'distance': 160.0,
'avg_arr_delay': 4.0,
'dest': 'CDV'}]}feature_layer.get_config()['feature_columns'].keys()